Skrevet som innspill til dokumentasjonssenteret 12.September 2008
Dette er ett innspill for å påpeke noen avklaringer som må gjøres for å avklare hvem loven skal gjelde for. Basert på de svar som kommer til de forskjellige problemstillinger vi angir her, vil det være mulig å argumentere for at all teknologi og systemer som brukes til å uttrykke, utveksle, mangfoldigjøre og publisere informasjon (nettsteder) må tilfredstille kravene om universell utforming fra 1. Juli 2011, eller det kan argumenteres at ingen nettsteder trenger å tilfredstille kravene om universell utforming før 1. januar 2021.
I loven står det:
Ҥ 11. Plikt til universell utforming av informasjons- og kommunikasjonsteknologi (IKT)
Med informasjons- og kommunikasjonsteknologi (IKT) menes teknologi og systemer av teknologi som anvendes til å uttrykke, skape, omdanne, utveksle, lagre, mangfoldiggjøre og publisere informasjon, eller som på annen måte gjør informasjon anvendbar.
Nye IKT-løsninger som underbygger virksomhetens alminnelige funksjoner, og som er hovedløsninger rettet mot eller stillet til rådighet for allmennheten, skal være universelt utformet fra og med 1. juli 2011, men likevel tidligst tolv måneder etter at det foreligger standarder eller retningslinjer for innholdet i plikten. For eksisterende IKT-løsninger gjelder plikten fra 1. januar 2021. Plikten omfatter ikke IKT-løsninger der utformingen reguleres av annen lovgivning.”
Og i Ot.prop 44.[2] Seksjon 2.3.1.2 står det: “…Eksempler på IKT som omfattes er internettsider, minibanker og billettautomater. Kravet om universell utforming skal ifølge høringsforslaget gjelde for neste utgave eller løsningsversjon etter denne fristen…”
Diskusjonen står om begrepet “Nye IKT-løsninger” og hva kan betraktes som en ny IKT løsning med tanke på hvordan nettbasert informasjon i dag håndteres.
For å forstå problemstillingen er det viktig å skape en forståelse for hvordan moderne nettbaserte løsninger fungerer. Og at de fleste nettbaserte løsninger i dag er bygget opp etter de samme prinsipper. Det er også en konflikt mellom begrepene “neste utgave eller løsningsversjon” og “Nye IKT-løsninger”.
Men siden det står Nye IKT-løsninger i lovteksten vil vi første omgang ta utangspunkt i de utfordringer begrepet – nye – har i forhold til hvordan en publiseringsløning er bygget opp.
Hvis vi tar utgangspunkt i følgende enkle skisse, vil vi for hver boks gjerne ha en egen komponent, og for hver pil kan det også være en løsning eller kommunikasjon mellom komponenter som tilsammen utgjør løsningen. Eksempler på pil som kan være en løsning er f.eks. en caching tjeneste, en messaging tjeneste el. En moderne løsning består i dag av mange forskjellige komponenter som hver utgjør sin spesielle funksjon, med en god lagdelt arkitektur og bruk av standarder er det også mulig å bytte ut enkelt komponenter uten at dette påvirker hvordan løsninger fremstår.
Hvis det med “Nye IKT-Løsninger” menes hvordan informasjon presenteres, uten tanke for de systemer som produserer og setter sammen informasjonen, kan nye bety at en ny side er publisert dvs. at det er kommet ny informasjon på nettstedet, eller det kan bety at det er ny design på nettstedet, endring av farger, bruk av bilder el.
Det er fullt mulig å ha ny design på ett nettsted uten at det har skjedd endringer i den IKT som brukes for å produsere informasjonen. Det er derfor viktig at det kommer en avklaring på hva som menes med “Nye IKT-løsninger”.
Det er også mulig å diskutere hva som menes med “underbygger virksomhetens alminnelige funksjoner”. Hvis vi ser på sidene til regjeringen eller stortinget kan det argumenteres for at disse nettsteder ikke underbygger virksomhetens alminnelige funksjon, og derfor ikke gjelder for loven. Det kan argumenteres at få nettsteder underbygger en virksomhets alminnelige funksjon, da det er få om noen virksomheter hvor dennes alminnelige funksjoner er nettbasert. Det er mulig at regjeringen og stortinget har som funksjon å drive informasjonsarbeide, og at en nettjeneste derfor er med på å underbygge den alminnelige funksjonen. Det samme gjelder f.eks. for banker, reisebyråer, flyselskaper, aviser mm.
En mer grundig gjennomgang av hvilke tekniske komponenter som er med på å utgjøre en nettbasert publiseringsløning kan være til hjelp for å forstå hvorfor en avklaring av “Nye IKT-løsninger” er viktig. Hvis vi tar utgangspunkt i [Figur 1] som gir en skjematisk oversikt over hvilke Hardware komponenter som er med på å bygge en nettbasert publiseringsløsning.
I [Figur 2] er det en oversikt over hvilke Programvare komponenter som vanligvis er med på å bygge en nettbasert publiseringsløsning. Dette synliggjør også viktigheten av en avklaring om “Nye IKT-Løsninger” gjelder for Maskiner eller Programvare, eller for egenutviklede programmer som er en del av Programvare rammeverk, som illustrert i [Figur 3].
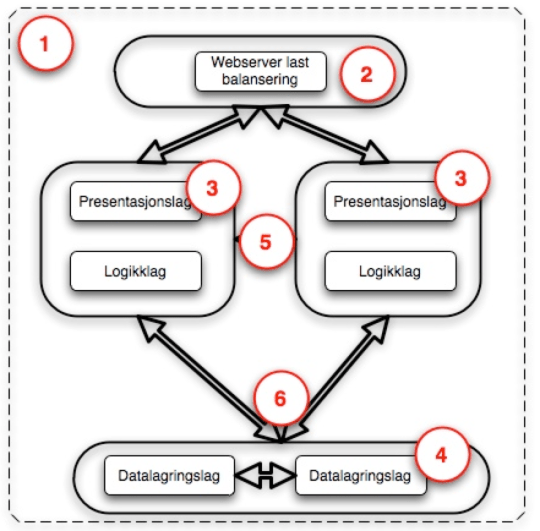
Figur 1
Figur 1: En forklaring av “funksjonene” med nummer
Her er det ikke tatt med nettverkskomponenter som er avgjørende for at systemene skal virke sammen og kunne kommunisere, som routere, brannmurer, og andre komponenter som også naturlig er en del av en IKT-løsning.
1) Dette kan betraktes som en løsning som i sum av alle andre komponenter utgjør den nettbaserte publiseringsløsning. Denne løsning tar ikke hensyn til kommunikasjon som foregår til sentraliserte tjenester som BBS, SSB eller spesielle saksbehandler systemer, slik kommunikasjon kan sees på som en pil ut fra (3).
2) Dette er ofte inngangsporten til en nettjeneste, dette er maskinen som svarer på http://www.xxx.no henvendelsene, og basert på hvilke henvendelse det er sender den til riktig bakenforliggende tjeneste, det kan være slik at bilder og andre statiske objekter sendes ett sted, mens mer dynamiske objekter sendes ett annet sted i det bakenforliggende systemene som er angitt med (3)
3) Dette er det laget som henter og setter sammen informasjon basert på den henvendelse som er gjort. Dette kan bety at det hentes informasjon fra flere forskjellige datakilder og hvor denne settes sammen til en helhet og sendes tilbake til mottaker. Dette er ofte funksjoner som tilbys automatisk gjennom mange forskjellige publiseringsrammeverk.
4) Dette er databasene hvor informasjonen som brukes og presenteres lagres, dette er det fysiske laget hvor informasjon faktisk er lagret. Dette kan være filbaserte systemer, det kan være relasjonsdatabaser, det kan være objektorinterte databaser el.
5) Avhengig av hvordan systemene er designet, og hvordan en nettøkt (session) ivaretas kan det være behov for å synkronisere informasjon mellom løsningene, dette gjøres da av en “caching” løsning som sikrer at alle løsningene og systemene har de samme informasjonsobjektene. Noen løsninger er slik designet at all trafikk fra en bruker går til samme maskin gjennom hele løsningen og gjør derfor en chaching løsning unødvendig.
6) For å sikre at informasjon er tilgjengelig hele tiden er oppetid avgjørende for mange løsninger, det er derfor behov for å sikre at alle løsninger kan erstattes av en annen hvis denne skulle slutte å virke. For å sikre at dette skal være mulig er det nødvendig å lagre samme informasjon i flere databaser. Ofte løses dette ved at løsningene har ett kluster av databaser som samarbeider og synkroniserer data mellom flere instanser. Dette er ofte spesielle løsninger hvor klusteret fremstår som en database.
Spørsmålet i forhold til “Nye IKT-løsninger” er om utskifting, eller oppgradering av en av komponentene nevnt i denne oversikt gjør at det blir en ny IKT-løsning. En oppgradering kan bestå av endringer i maskinvare, endringer i operativsystem som disse maskiner går på.
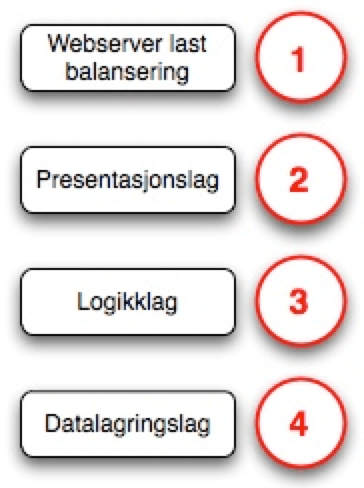
Figur 2
Figur 2: En forklaring av vanlige programmer som er med i en publiseringsløsning.
I følgende illustrasjon er begreper fra Java og OpenSource verden brukt, men andre miljøer som f.eks. Oracle/IBM/HP/Microsoft har tilsvarende løsninger med forskjellige navn.
1) Dette er programvaren som mottar en henvendelse, ser på typen av henvendelse og sender den videre til riktig sted, en veldig populær løsning for dette er Apache. (http://httpd.apache.org/)
2) Dette er et presentasjonslag hvor informasjon settes sammen og riktig koding legges på slik at informasjonen blir forståelig for det verktøy som mottar informasjoen. Vanligvis er dette informasjon som er kodet i HTML, XML eller andre kodeformater. Slike løsninger kan være f.eks. være Tomcat eller Jetty.
3) Dette er logikklaget hvor informasjonsobjekter bygges opp, hvor henvendelsen tolkes og nødvendig informasjon hentes fra f.eks. en database. I dette laget gjøres ofte utregninger og beregninger og sammenligninger av informasjonsobjekter for å sikre at riktig informasjon presenteres. Eksempler på slike løsninger leveres av Jboss, IBM-Websphere, Oracle, EasyWeb og de aller fleste CMS systemer.
4) Dette er datalaget hvor informasjon fysisk lagres. Dette er som oftest en database, populære databaser er PostgreSQL, MySQL, Oracle, Microsoft SQL server mm.
Avklaringer som må taes i forhold til “Nye IKT-Løsninger” er om utbytting av en av disse komponentene eller en oppgradering av de innebærer at det er en ny IKT-Løsning. Det må også gjøres en avgrensning på om en oppgradering av en av komponentene medfører at vi har fått en ny IKT-Løsning, eller om det er tilstrekkelig at en av løsningene er erstattet med en annen. F.eks. at en MySQL database byttes ut med en PostgreSQL database?
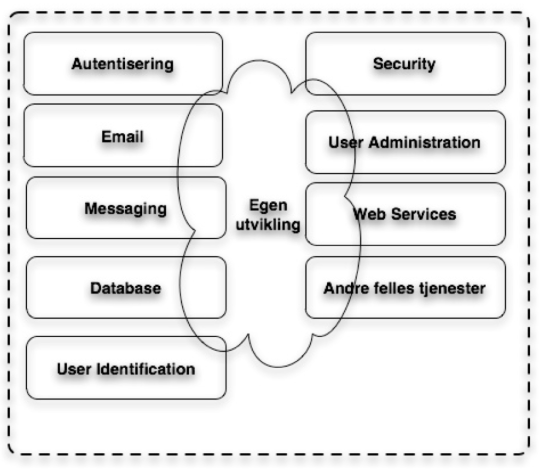
Figur 3
Figur 3: Programvare rammeverk
Hvis vi legger vekt på (3) under Figur 2, som et eksempel på hvordan et programvare rammeverk virker. Ofte er dette et standard rammeverk som tilbyr et sett av standardfunksjonalitet i tillegg er det et sett med veldefinerte grensesnitt for hvordan egne spesielle løsninger kan utvikles innenfor dette rammeverket. Det å utvikle nettbaserte løsninger innenfor et rammeverk gjør at det i prinsippet kun er nødvendig å utvikle funksjonalitet som er spesielt for nettstedet. Siden mange av komponentene er standardiserte er fullt mulig å bytte ut en enkelt komponent med en annen uten at dette påvirker de komponenter som er egenutviklet. Avklaringer som må gjøres er om oppgradering av rammeverk, eller enkelt komponenter i en slik løsning medfører at det er en ny IKT-løsning. Det samme gjelder også hvis det gjøres oppgraderinger av egenutviklede komponenter, eller hvis det legges til nye komponenter i en allerede eksisterende løsning. Eksempler på slike rammeverk er Jboss, EZ-publish, IBM-Websphere mm.
[1] http://www.lovdata.no/all/tl-20080620-042-0.html
[2] http://www.regjeringen.no/nb/dep/bld/dok/regpubl/otprp/2007-2008/otprp-nr-44-2007-2008-.html?id=505404
